

If you’re reading this, chances are you’ve realized there’s no going back to the way things were—artificial intelligence is rapidly changing how we do business, and that will only continue. Like any transformative technology, though, making the most of AI’s potential rests on getting the fundamentals right.
AI models are only as good as the data they’re trained on. Feed an AI system incomplete, messy, or biased data, and you’ll get unreliable, potentially disastrous results in return.
Garbage in, garbage out, as the old saying goes.
Just imagine a medical AI system misdiagnosing patients because of flawed training data or a self-driving car making dangerous decisions due to poorly labeled road images. Poor AI readiness can not only prevent you from maximizing the technology, but can even lead to worse results than if you weren’t using it.
In this article, we review eight crucial steps to priming your data for AI readiness. As AI inevitably becomes more widespread, this checklist will be increasingly handy!
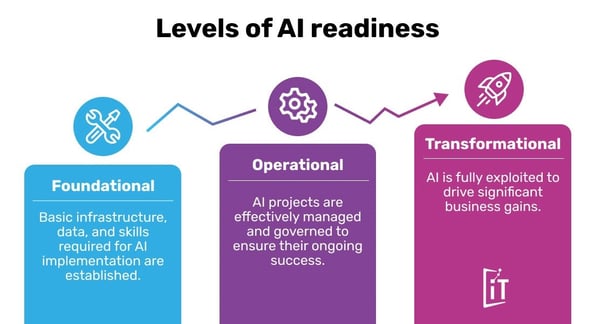
Levels of AI readiness
AI readiness refers to an organization’s preparedness to effectively implement and leverage AI for business benefits. This is not a one-time thing but rather an ongoing process of building capabilities across different areas.
Cisco finds that although 84% of companies think AI will have a “very significant” or “significant” impact on their business, only 14% of organizations worldwide are fully ready to integrate AI.
The different levels of readiness include:
- Foundational: This is the starting point, where organizations establish the basic infrastructure, data, and skills required for AI implementation.
- Operational: Here, the focus is on effectively managing and governing AI projects to ensure their ongoing success.
- Transformational: This is the most advanced stage, where organizations can fully exploit the potential of AI to drive significant business gains.
A core part of AI readiness is priming your data—ensuring that it is carefully groomed and structured to meet the unique demands of AI algorithms. It’s about checking that your data is a great fit for getting accurate predictions, smart decisions, and reliable output from AI models.
With this solid data foundation laid, the opportunities to innovate with AI are virtually limitless across all sectors.
1. Data collection & consolidation
This initial step involves compiling information from all the relevant sources scattered across your digital landscape, including:
- Internal sources: These include your organization’s internal databases, customer relationship management (CRM) systems, sales records, and even social media data.
- Cloud storage: Your company might use cloud storage solutions like Dropbox or Sharepoint in some capacity.
- The Internet of Things (IoT): If your organization utilizes smart sensors or connected equipment, factor this data into your collection strategy.
Once you’ve identified your data sources, the next step is data integration—combining all this information into a unified whole.
Data integration involves:
- Bridging the format gap: Data can come in various formats, such as spreadsheets, text files, and databases. Data integration tools can help convert these formats into a consistent language that your AI system can understand.
- Breaking down data silos: Different departments within your organization might store data in separate systems. Data integration helps break down these silos and create a centralized repository for all your information.
- Data harmonization: If you’re incorporating external data sets, there might be a need for data harmonization—ensuring that the data uses the same definitions and terminology to enable consistent analysis.
By consolidating your data and ensuring seamless communication between different sources, you’ve laid a solid foundation.
2. Data quality assurance
After assembling and integrating your data, it’s necessary to ensure that it’s reliable. Think of data quality assurance as a rigorous training exercise for your data, weeding out inconsistencies and inaccuracies before they throw a wrench into your results. 
Data quality assurance involves two efforts: cleaning and validation.
Data cleaning
This is where you meticulously comb through your data to identify and rectify errors, inconsistencies, and missing values.
- Error correction: Typos, inconsistencies, and incorrect formatting can all skew your AI results. Data cleaning involves identifying and correcting these errors.
- Missing value imputation: It’s inevitable that some data points might be missing. Data cleaning involves employing techniques like averaging or statistical methods to fill in these gaps responsibly. It’s crucial to document these processes to ensure transparency in your data handling.
- Format standardization: Data such as dates, currencies, or measurements can be presented in various formats. Data cleaning ensures that all your information follows a consistent format for seamless analysis by your AI algorithms.
Data validation
While data cleaning is a one-time effort, data validation is an ongoing process. It involves establishing procedures to continually assess the quality and accuracy of incoming data so that it meets predefined standards and formats. Think of it as a quality control checkpoint where you regularly verify that your data maintains its integrity.
By implementing a robust data quality assurance process, you’ll guarantee that your AI is working at its best, which will help keep you competitive and profitable.
3. Data structuring & organization
For your AI to effectively analyze data, it needs to be presented in a clear and organized manner. Data structuring involves organizing your information into a format that aligns with your AI’s needs and analysis goals. Think of it as redrawing a map: clearly labeling landmarks, using consistent symbols, and checking that the route is easy to follow.
Here’s a breakdown of the key components:
- Data categorization: The first step is to classify your data into relevant categories that make sense for your project. For example, if you’re building an AI model to predict customer churn, you might categorize your data into customer demographics, purchase history, and support interactions.
- Data formatting: Once categorized, ensure that your data adheres to a consistent format. Though standardizing date formats and using consistent units for measurements can be considered part of data cleaning, it is also critical to proper structuring. This can include encoding categorical data as well (e.g., assigning numerical values to different product categories).
- Schema definition: A schema acts as a blueprint for your data, defining the structure and meaning of each data point. You can think of it as the legend on a map, explaining what each symbol represents. A well-defined schema ensures clear communication between your data and your AI model.
The clearer and more consistent your road map, the easier it is for your AI implementation to extract valuable insights and deliver accurate results.
4. Data governance & compliance
As with all powerful tools, data used for AI needs to be handled responsibly. Data governance and compliance establish the guiding principles for managing your data ethically, securely, and in accordance with relevant regulations. It functions as a set of rules and processes ensuring that everyone involved acts responsibly and protects valuable resources.
- Data ownership: Clearly define who owns and is accountable for different data sets within your organization. This maintains data quality and fosters a sense of responsibility.
- Data access controls: Not everyone needs access to all your data. Data governance dictates who can access specific data sets, what they can do with it (e.g., read, edit, or delete), and for what purposes. This minimizes the risk of unauthorized access and misuse of sensitive information.
- Data security measures: Protect your data from unauthorized access, breaches, and accidental loss. Data governance helps by implementing security measures like encryption, access controls, and secure data storage practices.
- Data quality standards: Maintaining high-quality data is crucial for AI success. Data governance establishes guidelines for data collection, cleaning, and ongoing monitoring so that your data remains accurate, consistent, and reliable.
Depending on your location and industry, data privacy regulations like GDPR or CCPA might apply. Data governance aligns your data handling practices to these regulations, protecting user privacy and mitigating legal risks.
5. Data enrichment & augmentation
Data enrichment and augmentation are techniques for enhancing your existing data to unlock its full potential.
Data enrichment
This involves adding data sources to your existing dataset to improve its value and relevance for AI models. This can look like purchasing access to industry-specific datasets or partnering with external data providers. The goal is to find valuable insights and perspectives that your internal data might lack.
In some cases, generating synthetic data can be a valuable addition. Synthetic data is essentially artificial data that mimics the characteristics of your real data. This can be particularly useful when dealing with limited datasets or situations where acquiring real data might be ethically or legally challenging. However, it must be used cautiously and transparently.
Finally, don’t underestimate the power of human expertise! Incorporating insights from business analysts, domain experts, or marketing teams can enrich your data by adding meaning beyond the raw numbers.
Feature engineering
By manipulating existing data points through calculations or transformations, you can create new features that might be more informative for your AI model. For example, if you have data on customer purchase history, you can create a new feature that calculates the average purchase value per customer. However, not all features are created equal—some might be redundant for your AI model’s specific task. Feature selection involves identifying and selecting the most relevant features that will most significantly affect your model’s performance.
6. Data annotation & labeling
Data annotation involves adding labels or tags to specific data points within your dataset. AI techniques like supervised learning require this specific type of data preparation rather than just a general context. 
Data annotation can include:
- Image recognition: For tasks like object detection or image classification, data annotation involves outlining objects within images and assigning them relevant labels. For example, annotating an image for self-driving car development might involve labeling objects like pedestrians, traffic lights, and road signs.
- Natural language processing (NLP): When working with text data, data annotation might involve tasks like sentiment analysis or topic modeling. Here, annotators would label sentences or documents with their sentiment (positive, negative, or neutral) or categorize them based on the underlying topic.
- Speech recognition: For AI models that process audio data, data annotation might involve labeling specific sounds or phrases within audio recordings. This is used when training speech recognition models in virtual assistants or automated call centers.
Data annotation tasks are often completed by human annotators, although advancements in machine learning are leading to the development of automated annotation tools.
The data landscape is also constantly evolving, and so should your data annotations. As new information emerges, it’s crucial to update and refine your data labels. Remember: The quality and accuracy of data annotation can significantly impact the performance of your AI model!
7. Data infrastructure & tools
Data infrastructure refers to the technological foundation that enables you to store, manage, and process your data effectively for AI applications. In many ways, data infrastructure is the bedrock that supports efficient data preparation and analysis.
Here are some typical considerations:
- Storage solutions: The type of data storage you choose depends on the volume, variety, and velocity of your data. For smaller datasets, traditional relational databases might suffice. However, for larger, more complex datasets, distributed file systems or cloud-based storage solutions might be necessary.
- Computing power: Analyzing large datasets requires significant processing power. Depending on your project’s needs, you might choose on-premises servers, high-performance computing clusters, or leveraging the processing power offered by cloud platforms.
- Data management tools: A variety of data management tools can automate and streamline data preparation tasks. These tools can help with data integration, data cleaning, transformation, and even data annotation workflows.
Choosing the right tools
Selecting the most suitable data infrastructure and tools depends on several factors, including:
- The complexity and scale of your AI project: Larger projects with complex datasets will require more robust infrastructure and tools than smaller-scale projects.
- Budget: Distinguishing between must-have and nice-to-have features can help navigate budget-induced trade-offs
- Technical expertise: Consider your team’s expertise (including in-house and expertise supplied by partners like iTalent Digital) when deciding between building custom data solutions or utilizing pre-built tools and platforms.
- Legal and security considerations: Applicable regulatory and security obligations may dictate specific requirements.
8. Building a data-centric culture
Even the most meticulously prepared data remains inert without a culture that encourages actually using it! A data-centric culture empowers everyone in your team to understand the value of data and how it works to achieve your goals. Cultivating this collaborative mindset is a long-term process with a number of important facets:
- Education and training: Equip your team with the knowledge and skills to understand data fundamentals and analysis techniques and their role in AI projects.
- Breaking down silos: Data often resides in departmental silos, hindering the organization from achieving a holistic view of its information. Fostering collaboration among data scientists, IT professionals, and business units through regular workshops and knowledge-sharing sessions can bridge these gaps.
- Leadership by example: Leaders play a critical role in setting the tone for a data-centric culture. By actively using data to inform decision-making and championing data-driven initiatives, leaders inspire others to embrace this approach.
- Metrics and measurement: Success breeds enthusiasm. Establish clear metrics to track the impact of your AI projects and how they translate to business value. Showcasing these successes motivates teams and reinforces the data-centric culture.
- Experimentation: Not all projects will be slam dunks! Encourage a culture of experimentation where calculated risks and learning from failures are valued. This keeps pushing your organization to be on the cutting edge.
How iTalent Digital can help
There’s a lot to do when keeping up with integrating technologies like AI. Specifically, there’s an opportunity to transition your organization’s data management to the future and get ahead of your competitors. On the other hand, making the wrong decisions can cause your organization to fall behind significantly.
iTalent Digital takes a pragmatic, tech-driven, and consultative approach to BI, data and analytics, and digital transformation. Our industry-leading data management and governance model is further enriched by our AI engineers, partnerships with leading technology providers, and full-stack DevOps support.
Contact me at itbi@italentdigital.com to book a free consultation and discover how iTalent can transform your data into future-ready fuel for your success.
You may also like:
Keeping an eye on the people in an AI-infused world

